TOP PAGE
このブログの目的
私の勉強したことで、一日一つ備忘録兼日記として書いていくこと。
後々、本業のITなことも書きたいとは思っているが、現在は勉強へのモチベーションと義務感のため。
Bリーグ・日本代表参戦・観戦歴
初めに
フォーマットは現在検討中ではありますが、最近は待っているバスケ観戦について、ログを残そうと思い記載。
趣味系の話をちょろちょろと書いてみようかなと思って、こちらを再開してみます。
- 初めに
- 参戦歴
- 代表戦
- 2023-2024 シーズン
参戦歴
続きを読むオペレーティングシステム 「第1単元 OSの概要と歴史」
最近、生涯学習とか大事だよな〜と思っており、いくつかのmoocを覗いています。
その中でお仕事関連でOSについて学ぶため、「オペレーティングシステム」の講義を受講してみました。
まずは第1単元 OSの概要と歴史について気になったことや為になったことをまとめてみました。
オペレーティングシステム2020:F00000131 - Fisdomホームページ
ちなみに、fisdom今年の9月でサ終なんすね。。。始めたばかりなのに。。。
OSの概要
OSとはなんぞや。「使いづらい計算機を効率よく利用するためのもの」
使いづらい計算機とは
ディスク上に保存したデータを直接見るとディレクトリ構造なんてないし、計算ロジックのキーとなるCPUをそのまま使うのは難しい。
そのあたりの特性を隠蔽して利用者が使いやすいようにする。効率よく利用とは
動的なメモリアロケートとか、マルチユーザに対して適切にプロセスを振り分けたり、動作が遅いI/O機器にCPUが引っ張られないようにするなど
計算機のリソースを効率的に利用する。
OSの歴史
なぜ歴史?
OSの歴史はハードウェアの刷新と切っても切り離せない関係があるため。
なぜその機能があるのかを理解するために必須。
1940年代(プログラマブルではない計算機から。。。)
この時代はリアルハードコーディング(プログラムごとに配線をし直していた)
それを変えたのが「EDSAC」
管の中に水銀を満たして片側から超音波のパルスを与えると、 超音波は水銀中を伝わって反対側に届き
これを電気信号に変えてまた超音波のパルスにして管に戻し、 水銀の中で循環する超音波のパルスとしてデータを記憶させていた。
参考 : https://www.komazawa-u.ac.jp/~takai/kougi/EC.pdf
これにより、プログラムはこの水銀遅延管のデータを読み込む形に変わり、以降はこの形式(ストアードプログラム方式)に変わっていった。
1950年代前半(真空管の時代。OSはまだ登場していない)
この時代は計算機を動かす人と、計算機にプログラムをする人と、計算機を保守する人がすべて同じで
その人が計算機を独占していました。
真空管もすぐ壊れて(利用している個数が多いため、そのうち一つが壊れるのも時間の問題で)信頼性も低かった。
なお、最初に作成された商用計算機のUNIVAC 1を作成した会社は経営統合の末、UNISYSになっている。
1950年代後半〜60年代前半(トランジスタが実用化。ジョブバッチ処理の時代へ)
1956年にノーベル物理学賞を受けたトランジスタは、1947年には発明されていたものの真空管に一歩遅れて1954年に製造開始。
めちゃ高い計算機だが、作業員が手作業で操作していたため計算機の稼働が止まっていることもしばしば。
ひと塊の処理をジョブと定義し、それをひとまとめに投入する処理をバッチ処理とし、ジョブのバッチ処理を行うためにOSのようなものが作られた。
パンチカードをひとまとめにし、オペレーター(人間)の代わりにOSにジョブを渡して、OSが適宜計算機にジョブを打ち込んで結果を受け取る。
そのジョブを管理する言語をJCLという。また、この時代にFORTRANやCOBOLが生まれている。
1960年代〜70年前半(IC!計算機高速化!ディスクは遅い!そして、計算機のアーキテクトが各社でバラバラ!)
トランジスタの小型化が進み、トランジスタを集積したICが登場。計算機は高速化。
ただ、ディスクがそれに比べてめちゃくちゃ遅いため、入出力がネックになってきた。めっちゃプロセッサ遊んでるわ〜。
じゃあ、あるジョブの入出力待ちのときに、他のジョブをプロセッサ上で動かしましょう。マルチプログラミング
ジョブの入出力が終わったときに、次のジョブしたいしどう知らせようか?割り込み
複数のジョブが単一のプロセッサ上で並行で動いててややこしい!スケジューリング
あるジョブが、他のジョブのメモリ上のデータを見ちゃうことない?保護機構
IC時代のOS OS/360
アーキテクト合わせましょう!SYSTEM/360 IBM
安い計算機から高性能な計算機に移行するのが容易!やったね。アポロ11号でも使われたらしい。
SYSTEM/360上で動くのがOS/360。マルチプログラミングもできるよ。
IC時代のOS Multics
1964年からGEとAT&Tベル研究所が共同で開発(1969年にベル研究所は離脱しUNIX開発へ)
高可用性を目指して様々な機能が盛り込まれ、電話や電力サービスのような「コンピュータ・ユーティリティ」を目標としていた。
そのためソフトウェア構造のモジュール化だけでなく、ハードウェアもモジュール化され、必要なリソース(計算機能、主記憶、ディスク装置など)を追加するだけで拡張可能な構造を目指した。
ファイル毎のアクセス制御リストによって柔軟な情報共有が可能だが、必要に応じて完全なプライバシーも提供できる。技術者がシステムの性能を分析できる機構も標準で組み込んでいて、様々な性能最適化機構も組み込まれた。
ただ、時代がハードウェアが追いついてなかった。現在の計算機システムの基盤となる機構が多く含まれる。
IC時代のOS UNIX
1969年からAT&Tベル研究所で開発スタート。言わずもがな。みんな大好きUNIX。
プログラマに重点をおいた開発。
1970年代〜80年代 (LSI時代)
半導体技術が進歩したものの、人間の要求も進化。。。
TSSや多重仮想記憶など、複数人が同時に計算機を利用するための技術が発展。CPUのマルチコア化や仮想化がより進んだ。
仮想記憶方式とは、ユーザからは主記憶装置より大きなデータが見えるが、主記憶装置上には必要なデータのみを保持し、それ以外をディスクなどの補助記憶装置上に保管する方式。
それにともない、フラグメンテーションの解消や記憶保護などが実装される。
1990年代(分散処理・ネットワークの時代)
プロトコルなどが・・・
2000年代(分散処理・クラウド・保有から利用へ)
計算機リソースの保有から、手元になくても利用できるように。。。
chromebookのセットアップ時に使ったもの
昨日、以下のchromebookを購入したので、その際に必要になった設定とかを備忘録として記載します。
C223NA-GJ0018 シルバー グーグル Google")
- 発売日: 2020/06/12
- メディア: Personal Computers
ちなみに、私は英字配列のキーボードを購入しています。仕事でもプライベートでも英字配列のキーボードを利用しているので。
スクショのとり方
この記事を記載するためにも調べました。
「Ctrl+Shift+すべてのウィンドウを表示キー」になります。 chromebookはFnキーがない代わりに、特定の機能が設定されているボタンがあります。
scrollの反転(macbookと同じ方向に合わせる)
参考 : Chromebookのタッチパッド・マウススクロールの方向を逆にする方法 | むろすブログ Chromebook のタッチパッドを使用する - Chromebook ヘルプ
keyboardの設定(英字キーボード特有)
自分は英字キーボードを利用しており、初期設定では日本語キーボードの設定になっていたので、別途対応必要。
設定ー>詳細設定ー>言語と入力方法 と選んできて、「入力方法を選択」

「入力方法の追加」をクリック

「日本語(US)キーボード」と「英語(アメリカ)」を選択し、「追加」をクリック

そうすると、以下のように4つの入力方法が記載されている
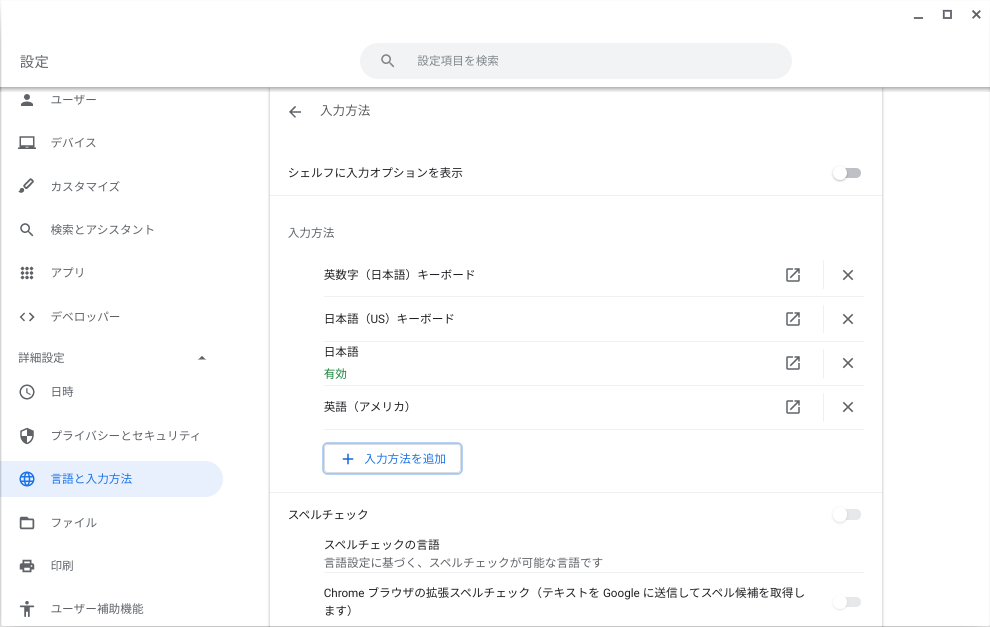
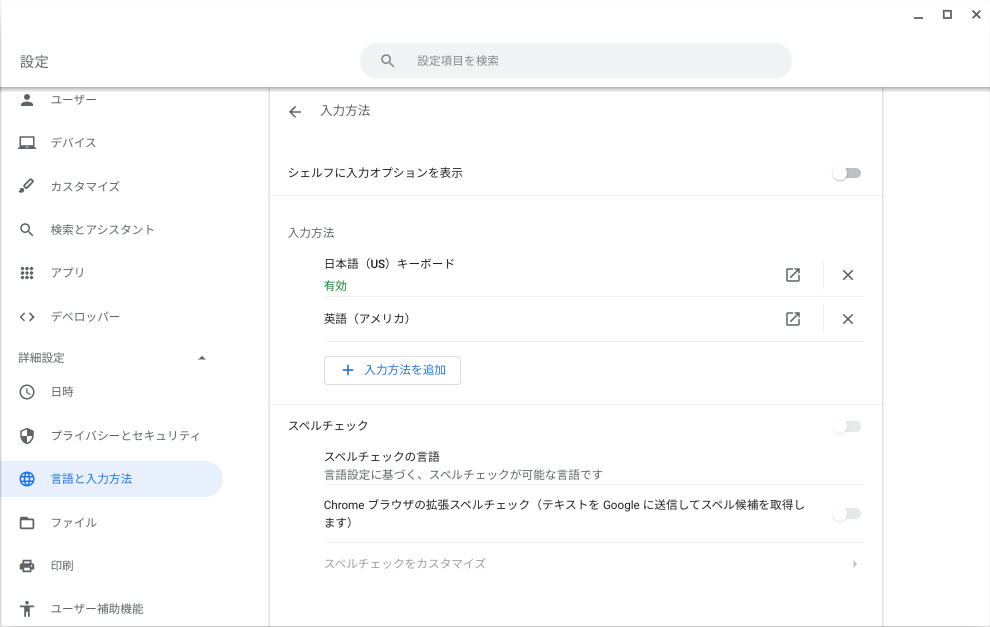
日本語配列の入力を削除(右の☓ボタンをおして)
MySQLを根っこからじっくりと
0. 初めに
インフラエンジニアとして早6年。その中でもMySQLは切っても切り離せない存在となっています。
私がインフラエンジニアになった時から既にそうであったのですが、最近のミドルウェアは軽く動かすだけであれば、正直インストールして起動するだけで問題ないです。
なので所謂スタートアップ系とか軽めのアプリケーションには、もうインフラエンジニア専業の奴はいらなくなってくるんじゃないかと思っています。(下手な使い方して、動かないとかはあると思いますが、どっちみちエラーログ見てググるだけなので、それなりのサーバサイドエンジニアであればできますし...)
自分は数万rpsや数千qpsの負荷を裁く必要があるサービスを扱う都合上、多少は深くミドルウェアを触っておりますが、
触る部分といえばmy.cnfの中身からbinlogを吐き出すディスクの分散程度です。もっと根っこのところは正直よくわかっておりません。
より深掘りして、根っこからいろいろ理解したい。というモチベーションで少しずつ記事を書いていこうと思っています。
1. 構成
ごりっごりに自分が気になる箇所をいっぱい書いてやろうと思っています。
また、このページに全部書くと大変なことになりそうなので、1テーマにつき1記事に分けて書いていこうかと考えています。
まずは、テーマ決めから...
1.1 ibdファイルの中身について
まずは、どのような仕組みで書き込まれて行っているのか。また、deleteされた際の挙動などが気になっています。
ファイルフォーマットのAntelopeやBarracuda周りも調べたい。
innodb_flush_method周りも調べてみたい。
1.2 木構造やインデックス
インデックス。張ればいいって話じゃない。どういう構造でインデックスが張られているのか。というところから調査したいと思っています。
また、query optimizerの挙動が変わる箇所なども気になっています。show engine statusやExplain 周りの挙動も含めて確認する形になるかと考えています。
1.3 InnoDBとMyISAM
なんやかんやで最近はInnoDB使ってるけど、MyISAMとの違いやトランザクション分離レベルの話も触れたい。
参考 MySQL の Repeatable Read と RocksDB の楽観的トランザクション解説 | 株式会社インフィニットループ技術ブログ
多分、innodbの仕組みを詳しく調べるだけでも1記事作れそう。
Lockの仕組みも見たい。
1.4 GTIDとPosition Based Replication の違いや詳細
binlog/relaylogのとりかたから、それぞれの特徴をざっくりまとめたい気持ち。
1.5 InnoDB Cluster
各機能の挙動や、マスター昇格する際の挙動やスレーブ復帰の処理などを詳しく調べたい。
あと、ここが欲しかったというポイントも
1.6 Internal Temporary Tableについて
これに関してのbugを踏んだこともあり、内部テンポラリーテーブルについて知見を深めたい
これとかは参考 第129回 Internal Temporary Table(内部テンポラリテーブル)について[その1]:MySQL道普請便り|gihyo.jp … 技術評論社
1.7 doublewrite buffer
1.8 5.6以降の各バージョンの比較
【mundi先生】世界史20話プロジェクト004 古バビロニア・インドヨーロッパ系民族
前回の続きから動画を見ていきます。
あらすじ
人・旧石器時代
猿人・原人・旧人・新人
--- 1万年前 ---
新石器時代
農耕や牧畜を行って、雨水を元に乾地農法
灌漑農法 -> 安定した生産。権力や文明が生まれる
古バビロニア王国
アッカド人を征服
セム語系のアムル人が建国
ハンムラビ王 ・・・ 古バビロニア最盛期の王
ハンムラビ法典制定
特徴
- 復習法(目には目を歯に歯を)
- 身分法(奴隷に対して行った罪は軽くなる)
古バビロニア王国は、小アジアから来た異民族によって滅ぼされる
インド=ヨーロッパ系遊牧民の侵入
小アジアに国家建設
古バビロニア王国を征服
馬に乗り、戦車を使用
鉄製武器を使用 ヒッタイト=鉄!
エジプト(新王国時代)と戦うことになる カデシュの戦い
ヒッタイトは【海の民】に滅ぼされる
- ミタンニ
メソポタミアの北方の山岳地帯を支配したミタンニ人が建てた国 しかし、ミタンニを構成していた多くの人々は、もともとコーカサス地方にいたフルリ人(フリ人ともいう)であったという。
コーカサス地域とはカスピ海と黒海に挟まれた地域でコーカサス山脈と、それを取り囲む低地からなる面積約44万km2の地域である。
コーカサスの漢字表記は高加索。北にロシア南にトルコがありジョージア・アゼルバイジャン・アルメニアがあります。
参考 : https://www.y-history.net/appendix/wh0101-026.html https://www.y-history.net/appendix/wh1301-058.html
ちなみに英語のコーカサス、ロシア語のカフカースとも古代ギリシア語: Καύκασος (Kaukasos; カウカーソス)に由来する。 「カウカーソス」自体は、プリニウス『博物誌』によるとスキタイ語のクロウカシス(白い雪)の意である。
名に「コーカサス」とあるが、コーカサス地方に生息しているわけではない。(「caucasus:コーカサス」とは、古代スキタイ語で「白い雪」を意味する「クロウカシス」に由来するギリシア語で、コーカサスオオカブトの上翅にある光沢から名付けられたもの。)
前14世紀には王家に内紛が起こったことと、ヒッタイトと戦って敗れたことで衰退した。
情報集められませんでした。
GAFA 世界を席巻するプラットフォーマー
「2020年3月増刊号 最新時事用語&問題」 から、気になったことを書いていこうと思います。 Amazon CAPTCHA
今日は「経済・金融 1」の「GAFA 世界を席巻するプラットフォーマー」をちょいと調べてみます。
概要
GAFAとは・・・
以下の4社の頭文字をとったもので、特に米IT企業の中でも巨大で影響力も大きい企業を指します。
- G : Google
- A : Apple
- F : Facebook
- A : Amazon.com
業界的にもこれらとの関わりもかなり深いため、奴らの凄さはみにしみます。(Facebookは最近よく知りません。)
あと、Microsoftも含めたGAFAMやFAMGAなどの呼ばれ方をするのもありますね。
プラットフォーマーとは
これもキーワードと思います。
例えばスマホにしても、現状はiOSとAndroidの二強(black berry? windows phone? tizen?...)で、その上で動くアプリは他社が作って、その中で課金ができて儲けれる。とか
SNSにしてもFacebookはユーザの情報をガッツリ集めて、広告をパーソナライズできるなど。
いわゆる、彼らが作ったサービスの上で他社が商売やサービス提供をして、ユーザはそこに集まりお金の動きが発生する。そして、そのお金の動きの数%をもらうのが彼らのやり方であり、プラットフォーマーというものですね。
他のタイプのプラットフォーマー
他のタイプと言いつつ、GAFAの企業がなを連ねるのも多々ありました。
BATH(バース)
中国の大手IT系企業の頭文字をとったものですね。(知らなかった)
- B : Baidu
- A : Alibaba
- T : tencent
- H : Huawei
FANG(ファング)
特にメディア系につよい大手プラットフォーマー
A がAmazonかAppleか迷った(Appleも最近動画のサブスクやってた気がした)ので調べたら、こういう略称は他にもありそうですね。
MANT(マント)
マジで初耳。そこでそんなワード作るんだ〜って感じ。FANGと全くかぶってないのはいい感じ。
巨大化するプラットフォーマーたち
その性質上、人や金が集まれば集まるほど良質なコンテンツが配信されたり、サービスが出てきたり、プラットフォームを利用する企業が増えるため、これらの企業はサービスが国境を超え非常に大きなものになります。
また、企業体系も新しく(米国と日本の税制の違いもありますが)研究開発費を大量に利用できたりするため、近傍へのビジネス展開やそれの改良も早いため、徐々に既存のサービスを食って売り上げを上げていく動きもあります。
直近ではGAFAM5社の合計時価総額が、東証1部の全企業の時価総額を超えたとのこと。
プラットフォーマの抱える問題
大量のデータが集まるプラットフォーマーと、EUの個人情報保護の流れから、個人情報保護のためのGDPRに違反しているということで、62億円の罰金が課された。
また、プラットフォームの利用料についても不満が上がっている。
例えば、iOSのアプリ内課金には数十%がApple側にとられて、残りがアプリ開発者に入るなど、プラットフォームが独占されているため払わざるを得ない状況になってはいるものの、不満は上がっている。
あとは、租税周りでも既存税法が追いついていないため問題が多く、やりとりや個人情報周りでも国家対GAFAの対立もあるそう。
フェルマーの最終定理わからんから、それっぽいの計算してみた。
ちょうどヨビノリさんのこの動画を見てた(半分寝てたのであまり理解できてないが。。。)時に別のパターンだったらどうなるだろうと思って計算してみた。
なぜしたか
これって、n乗される数とnが一致していない(or n乗される数の方がnより小さい)から成り立たないのかな〜と思い、まずは手短に確認してみたくて。
何をしたか
やってみたのはこちら。イメージとしては、3個の自然数のそれぞれの3乗を足し合わせると、何らかの自然数の3乗になるかを調べてみました。
これ、名前あるのかな〜?
どうしたか。
クソみたいなpythonのコードを書いて、計算した結果の中からそれっぽいものを抜き出す。ということをしました。
#!/usr/bin/python rt = 1.0 / 3 for i in range(1,40): for j in range(i,40): for k in range(j,40): sum = (i**3) + (j**3) + (k**3) b = sum**rt print("i=",i,"j=",j,"k=",k,"b=",b)
簡単にコードの説明をすると、とりあえず変数3つ用意して3重ループ作ります。
ただし、i<=j<=kになるようにしています。(同じ組み合わせの計算をしないように。)
そして、i,j,kをそれぞれ3乗した結果をsumに突っ込み、それを1/3乗します。(1/2乗とかであれば0.5とベタ書き出来ましたが。。。)
ただ、この計算方法だと、綺麗に1/3乗できないので、出力時は注意
どうなったか。
とりあえず、該当の計算を出力しました。
MacBook-Air:fermat2 Apple$ python multi.py | grep "\.9999"
('i=', 1, 'j=', 6, 'k=', 8, 'b=', 8.999999999999998)
('i=', 2, 'j=', 12, 'k=', 16, 'b=', 17.999999999999996)
('i=', 3, 'j=', 4, 'k=', 5, 'b=', 5.999999999999999)
('i=', 3, 'j=', 10, 'k=', 18, 'b=', 18.999999999999996)
('i=', 3, 'j=', 18, 'k=', 24, 'b=', 26.999999999999996)
('i=', 3, 'j=', 36, 'k=', 37, 'b=', 45.99999999999999)
('i=', 4, 'j=', 17, 'k=', 22, 'b=', 24.999999999999996)
('i=', 4, 'j=', 24, 'k=', 32, 'b=', 35.99999999999999)
('i=', 6, 'j=', 8, 'k=', 10, 'b=', 11.999999999999998)
('i=', 6, 'j=', 20, 'k=', 36, 'b=', 37.99999999999999)
('i=', 6, 'j=', 32, 'k=', 33, 'b=', 40.99999999999999)
('i=', 7, 'j=', 14, 'k=', 17, 'b=', 19.999999999999996)
('i=', 9, 'j=', 12, 'k=', 15, 'b=', 17.999999999999996)
('i=', 11, 'j=', 15, 'k=', 27, 'b=', 28.999999999999993)
('i=', 12, 'j=', 16, 'k=', 20, 'b=', 23.999999999999996)
('i=', 14, 'j=', 28, 'k=', 34, 'b=', 39.99999999999999)
('i=', 15, 'j=', 20, 'k=', 25, 'b=', 29.999999999999993)
('i=', 18, 'j=', 19, 'k=', 21, 'b=', 27.999999999999996)
('i=', 18, 'j=', 24, 'k=', 30, 'b=', 35.99999999999999)
('i=', 21, 'j=', 28, 'k=', 35, 'b=', 41.99999999999999)
('i=', 27, 'j=', 30, 'k=', 37, 'b=', 45.99999999999999)
結構ありました。
などなど。
わかったこと
パターンありますね。
上記にあるような数の倍数でも成り立つようです。
3,4,5 -> 6の場合は、以下リンク先で解いているようです。
marukunalufd0123.hatenablog.com]
結構ありそう。